



AI预训练模型在智慧政务中的实践
一、智慧政务背景与挑战
1、智慧政务发展背景
智慧政务是指采用人工智能等前沿技术,通过流程创新,整合跨部门资源,提升政府高效履职、便捷服务、智慧决策的社会治理能力,为公众、企业及政府部门自身提供智慧化的政务服务。
最新发布的“中华人民共和国国民经济和社会发展第十四个五年规划和2035年远景目标纲要”指出,要大力发展人工智能、云计算、大数据、物联网等重点产业,以及智慧政务、智能交通、智慧教育、智慧医疗等数字化应用场景,加快建设数字社会和数字政府。在智慧政务领域,“纲要”提出:推进政务服务一网通办,推广应用电子证照、电子合同、电子签章、电子发票、电子档案,健全政务服务评价体系。
2、智慧政务发展挑战
政务信息化通过多年的发展演进,各级政务部门先后建设了信息系统,有部分的部门还建设了数据中心,收集了大量的数据。但现有系统大多是解决部门内的业务问题,数据中心也仅限于数据收集和统计,并没有进行有效的数据挖掘,数据价值未能得到有效利用。
政务业务系统数据有明显的垂直领域特征,比如非结构化数据多、数据价值密度高、数据行文规范正式,但缺乏高质量的标注数据、缺少挖掘提炼。要在部门内部、跨部门,以及为公众用户提供高质量的数据服务,核心的问题之一是如何运用人工智能前沿技术,深入挖掘数据中的高价值信息。
人工智能领域在语音、视频等感知智能上发展迅速,但在以自然语言处理为核心的认知智能方面进展缓慢,难以有效支撑高质量的政务数据理解,形成有价值的数据,为政务应用赋能。近两年,以预训练语言模型为代表的人工智能语义分析技术得到了快速发展,为有效挖掘和提炼数据价值提供了基础。
二、AI预训练模型发展
1、AI预训练模型概述
随着深度学习的发展,包括卷积神经网络、循环神经网络、注意力机制在内的各种神经网络应用于语义分析的研究如火如荼,但由于语义分析任务的数据集不足以支撑将网络做深,无法将参数扩大,难以发挥具有深度神经网络网络深度和海量参数的表示能力,在实际应用中泛化效果不佳。
近几年的研究表明,在大型语料库上进行训练的模型可以学习到基础或者通用的语言知识表示,对后续的语义分析任务大为有益。这样既能避免神经网络在小数据上的过拟合的问题,也能避免每次从头开始训练新模型。
预训练模型(Pre-training mode)是指使用海量通用的文本语料进行无监督训练得到的语言模型。后续的语义分析任务包括分类、相似度计算、问答、纠错、摘要等任务可以基于预训练模型,结合领域数据进行调优(Fine-tuning)。
2、AI预训练模型发展阶段
AI预训练模型经历了两个阶段的发展:
第一个阶段,预训练模型以词嵌入(Word2Vec)技术为代表,通过设计模型,训练学习获得文本的语义向量表示。下游任务使用语义向量表示输入数据,选择合适的算法完成具体的分析任务。本阶段词嵌入表示的语义是上下文无关的,在深层的语义计算和应用效果依然有限。
第二个阶段,预训练模型不仅学习上下文相关的词嵌入,还学习包括语义关系、句子关系、问答等基础模型。在下游任务中,这些模型既能提供文本语义向量表示,还能利用下游任务的数据进行调优。本阶段以双向编码表示预训练模型BERT为代表,包括ELOM,GPT,BERT等。
ELMO
ELMO(Embedding from Language Model)。ELMO采用双向循环神经网络特征抽取架构,将每一个单词对应两个隐藏状态,进行拼接得到单词的Embedding表示。在不同的上下文得到与上下文匹配的动态词语义向量,比Word2Vec静态语义向量有了不小的进步。
GPT
GPT(Generative Pre-Training)。GPT是生成式预训练模型,采用的训练方法分为两步,第一步利用无标签的文本数据集训练语言模型,第二步是根据具体的下游任务,包括问答,文本分类等对模型进行微调。GPT继续采用单向的Transformer特征获取架构进行训练,使用文本的上文来表达文本语义。
BERT
BERT(Bidirectional Encoder Representations from Transformers)。BERT的结构如下图示,采用双向、基于注意力机制的多层Transformer编码特征抽取和预训练+调优两阶段架构。
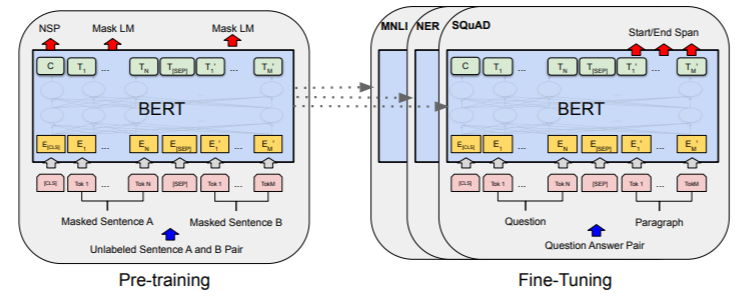
图1:Bert预训练+调优两阶段架构
BERT的训练包括两个任务,第一个任务是掩码语言模型,随机把一些字符掩码,通过预测掩码字符来训练模型;第二个任务是将两个句子拼接送入BERT模型,通过预测这两个句子的顺序关系进行训练。这样BERT在训练过程中不仅学习到了双向文本语义表示,还能学习到下游任务的基础模型。
总结来看,ELMO,GPT,BERT在编码器、训练方法、特征捕获能力不同,在实际的语义理解和分析应用中BERT具有非常大的优势。
BERT预训练模型
BERT预训练模型因为其应用优势,迅速发展成为模型家族,包括ERNIE,RoBerta,UniLM,Albert等典型变种。
ERNIE
ERNIE是通过集成外部知识来提升模型表达能力。ERNIE有两条路径,第一条路径是通过掩盖掉整个词语而非字符来提升语义表达能力,称为Enhanced Representation through Knowledge Integration。第二条路径则引入了基于知识图谱的语言常识信息,以提升模型的常识理解能力,称为Enhanced Language Representation with Informative Entities。
RoBERTa
RoBERTa(A Robustly Optimized BERT Pre-training Approach)采用了更大的模型参数、更多的训练数据、更大的批次数据量,在训练方法上采用动态掩码的方法,每次向模型输入样本都会生成新的掩码模式,在大量数据不断输入的过程中,模型会逐渐适应不同的掩码策略,学习不同的语言表征,更容易泛化。
UniLM
UniLM(Unified Language Model Pre-training for Natural Language Understanding and Generation)通过改进模型训练方法,通过扩展使模型同时具备自然语言理解和自然语言生成的统一预训练模型。
Albert
Albert(A Lite BERT)是轻量级的BERT模型。Albert通过矩阵分解技术对编码部分处理,大幅降低编码部分的参数量。通过参数共享减小提升训练速度;并将下一句预测任务调整为句子顺序预测任务,以便更好的学习句间语义关系。
三、AI预训练模型在行业的落地流程
AI在行业落地,首先是对业务需求的梳理和理解,总结语义分析的需求和业务数据现状;其次是根据业务要求进行语义方案的技术选型和建模;最后按业务应用要求集成应用、评估、改进,形成闭环。如下图示:
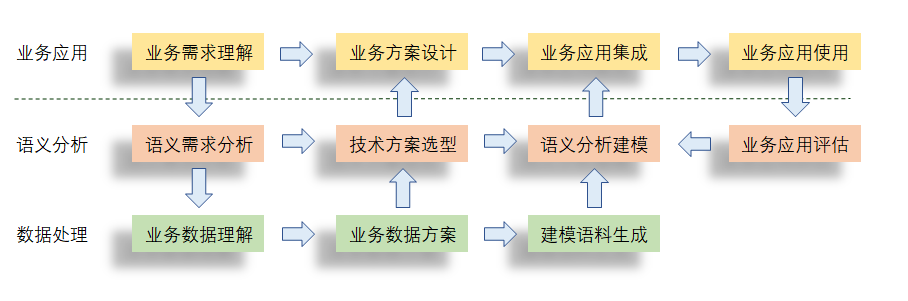
图2:行业应用落地流程
需求理解和分解
根据行业应用对业务流程智能辅助、知识抽取、信息服务等各方面进行需求梳理,将业务需求分解为语义分析任务,包括分类,聚类、查重,摘要,纠错,抽取,检索、智能推荐等。
行业预训练模型
学术界研究有两个特点,第一是大多只研究通用模型,和行业应用有差距,第二是为了效果不怎么考虑成本。在具体行业落地时,需要根据行业的数据特征分析以及成本分析,确定行业领域预训练模型的方案。
模型调优
在行业应用落地,模型调优可以有两个选择。第一方案是根据行业数据重新训练预训练模型,然后根据具体NLP任务进行模型调优。第二种方案是直接引用已经训练好的通用预训练模型,然后根据具体NLP任务进行模型调优。采用前者需要考虑行业数据和模型训练成本,采用后者需要根据业务应用选择合适的路径。
模型部署
业务语义模型在行业实际应用部署重点需要考虑的问题包括准确性、并发性能、响应时延等,在模型性能和模型成本之间寻找平衡点。可能的性能提升方案包括蒸馏、剪枝和量化等,需要根据行业应用的实际环境和需求评估选择。
效果评估与改进闭环
业务语义模型集成到业务应用,部署上线后可以通过采集应用效果,对模型应用效果评估,并将应用效果反馈至语义建模任务。通过在线应用的实际评估来不断改进语义建模,提升模型的服务效果和能力,形成改进闭环。
四、AI预训练模型在智慧政务中的应用
政务应用的典型用户包括终端用户、工作人员、主管领导。终端用户关注如何快速获取政务相关的政策、制度、流程,如何准确和快速便捷地办理相关的业务。工作人员关注如何快速进行业务审批办理,降低人力投入、提升工作效率。主管领导在业务的基础上更关注业务分布、业务趋势及有效措施,以满足决策的需求。
以某政务部门智慧应用为例,海泰方圆在调研业务场景、充分与业务用户沟通的基础上,深入理解用户需求和痛点,将用户的需求分解梳理,形成专业的AI需求,以通用NLP技术为基础,融合预训练模型技术,基于行业数据进行AI建模,快速完成落地。本应用为用户提供文献检索与推荐、摘要、纠错、分类、查重、筛查、落实承办部门、综述等十多项智慧化服务,在提升终端用户体验、减轻工作人员负担、智能辅助领导决策等方面获得了良好、显著的效果。
从技术到行业应用的成功落地,需要综合考虑业务理解、应用规划、技术开发、行业部署等方面内容。海泰方圆公司作为一家拥有核心技术的可信数据服务领军企业,在安全、人工智能、大数据等方面有深厚的积累,长期服务党政领域,通过将AI预训练模型技术结合行业应用实践经验,可以为用户提供快捷有效的智慧服务,助力电子政务往智慧政务的演进。








